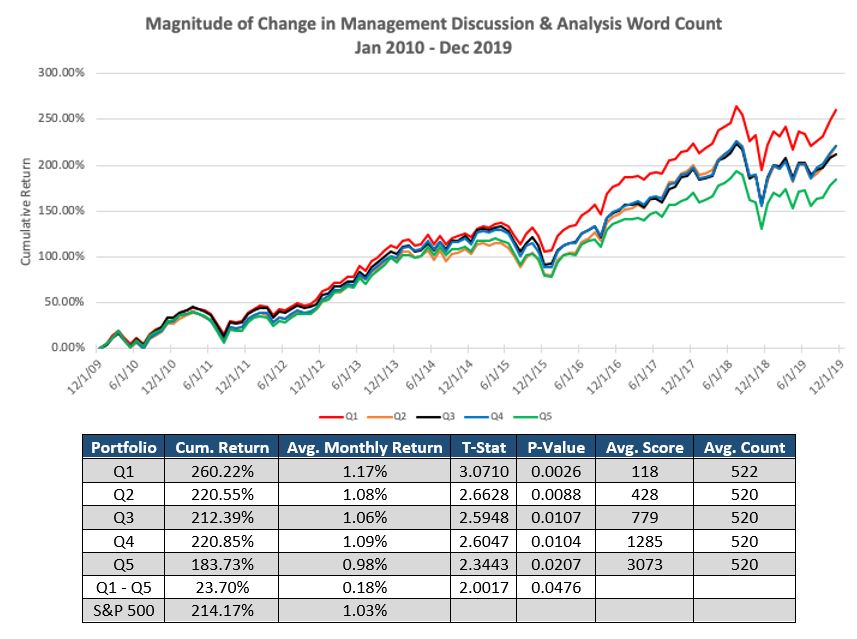
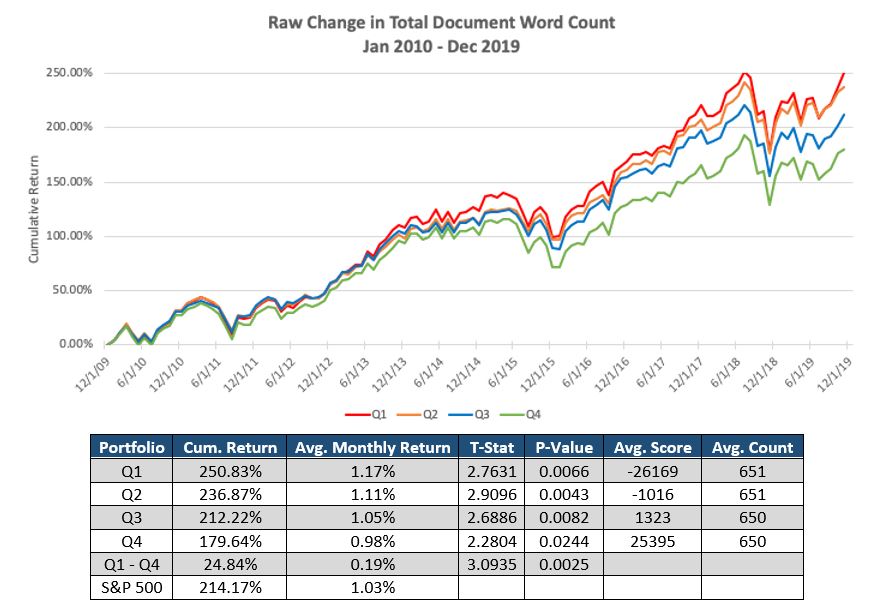
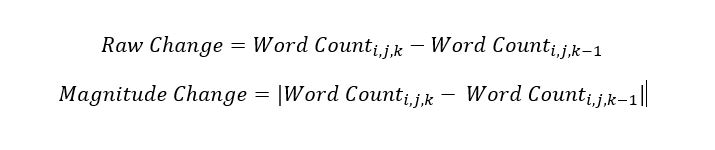Social Market Analytics, Inc. (SMA) in April 2021 released Global Machine Readable Filings (GMRF) in partnership with S&P Global Market Intelligence. Global Machine Readable Filings is the first product to provide parsed textual data of over 200 Countries Company Annual Reports, Quarterly Report, Semi-Annual and Financial Supplements across ~1.6M documents.
This blog will explore details of this offering and some of unique features. For Global filings there is no central repository of documents. S&P archived global filings for the last 20 years. At SMA we used our patented document processing technology to turn these files into machine readable JSON. The structure of each document is created by individual companies, so the structure is subject to change. For example, Company A can change formatting YoY. Since each company has its own format there are challenges from comparing Company A and Company B. The original files come as PDFs with significant variations: “Magazine style”, scanned documents and tables without HTML tags. Our machine learning algorithms have processed these files and successfully converted them to JSON.
Below are a few examples of parsing different file types. The SIKA 2018 Annual Report table of contents is below.
By reading the Table of Contents (TOC) we identify primary headings. In addition, we identify subheadings under Strategic Target Markets & Risk Management based off of font and structure variations which are not available in the TOC.
The next example is Credit Suisse Group 2017 AR. 
The SMA parser dynamically identifies Items, parts and subsections.
We use our Generic document parser to read and identify parts. Below is the strategy section broken into sub-parts.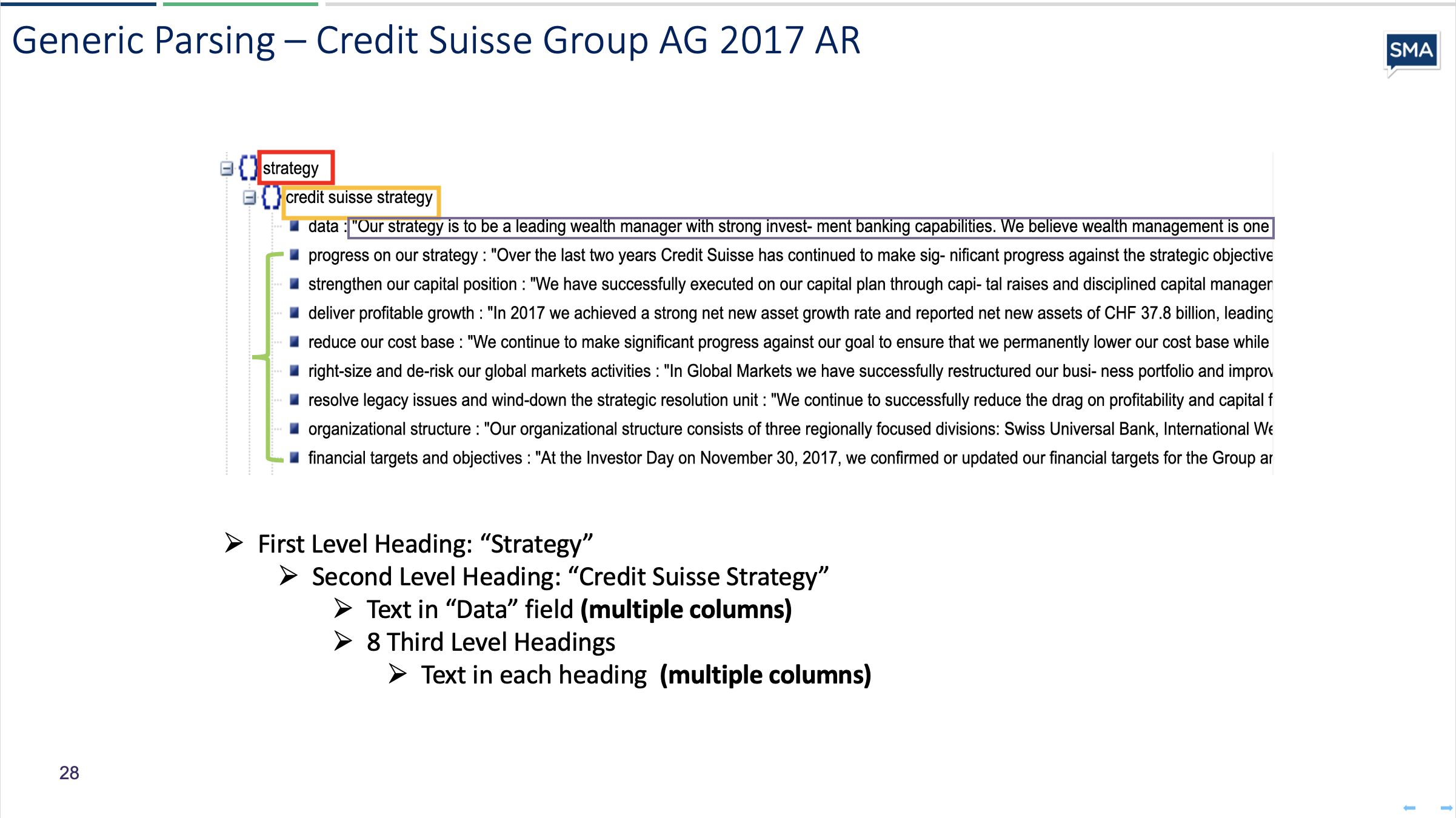
These are just two filings. As we mentioned there are 1.6 million documents in the archives and updates are provided in real-time through XpressFeed, Snowflake or through the SMA Filings API. To trial this product or learn more about other Social Market Analytics datasets please email us at ContactUs@SocialMarketAnalytics.com